





Что?
Все мы знаем, что представляет собой металлическая цепь. Это олицетворение силы и надёжности. Биткоин тоже имеет свою цепь, которая называется блокчейн. Блокчейн представляет собой цепочку ссылок, в которой каждая ссылка приходится на группу транзакций (блок транзакций) надёжным и криптографически защищенным способом.
Цепочки данных представляют вместо этого связанные между собой идентификаторы данных. Идентификаторы данных это не сами данные. И точно так же, как блокчейн не содержит биткоины, цепочки данных не содержат данные.
Почему?
Как они не используются? Если цепочки не содержат данных, то зачем они нужны?
Это очень важный вопрос, и от ответа на него нельзя отделаться. Нас можно уверить, что транзакция произошла в блокчейне, так как она позволяет знать, где находятся биткоины, как если бы они были реальной вещью. То же самое и с цепочками данных, мы можем быть уверены в том, что данные существуют, и в том, где именно они существуют. Однако в случае с цепочками данных, документы для идентификации реальны (изображения, видео и так далее). То есть, если мы знаем, что эти файлы должны существовать и можем идентифицировать их, то нам нужно просто получить данные и осуществить проверку. Сеть, которая одновременно хранит и проверяет данные по их ID, значительно выигрывает в эффективности и простоте по сравнению с блокчейнами, которые не могут хранить существенные объемы данных, например, файлы. Цепочки данных также могут использоваться для связи между собой различных сетей и блокчейнов, но здесь вы сможете снова спросить, зачем это делать, ведь дублирование не эффективно?
Обработка данных
Поэтому, если блок идентифицирует бесспорную информацию о файле, например такую, как хэш контента, он берёт данные и сравнивает их с подтверждённым блоком. Если блок показывает, что данные распознаны, то сеть согласилась принять на себя ответственность за целостность этих данных. Теперь мы можем в исторической переспективе подтвердить, что данные принадлежат какой-либо сети, и именно эти данные являются подтверждёнными. Это большой шаг вперед, поскольку многие думают — о, я могу легко сделать это с существующим инструментом XYZ, но через несколько минут убеждаются, что не всё так просто.
Как это происходит в сети
Теперь мы отходим от стандартного взгляда на одну правдивую цепочку и смотрим на её составные части, или представим себе децентрализованную цепочку в децентрализированной сети. Цепочку, в которой только очень небольшое количество узлов будет знать истинность некоторого небольшого набора данных, но сеть в целом знает всё о всех данных.
Нам снова нужно рассмотреть цепь немного ближе, и в этом нам поможет взгляд на эту картинку. Мы можем увидеть здесь ссылки и блоки. Это важный вопрос, на который можно опереться при дальнейших размышлениях. Например, в блокчейне ссылка является простой (чем проще, тем лучше, в безопасности во многих случаях чем проще, тем сильнее защита).
 Здесь же ссылка является целым блоком соглашения. Эти ссылки на самом деле являются набором имён и подписей участников группы, которые на настоящий момент достигли соглашения по этой цепочке. Каждая ссылка должна как минимум содержать большинство предыдущих ссылок. С каждым изменением в группе новая ссылка создаётся и присоединяется к цепочке. Между этими ссылками лежат блоки данных, которые представляют идентификаторы реальных данных (хэш, имя, тип и так далее). Снова они подписаны большинством предыдущих ссылок.
Здесь же ссылка является целым блоком соглашения. Эти ссылки на самом деле являются набором имён и подписей участников группы, которые на настоящий момент достигли соглашения по этой цепочке. Каждая ссылка должна как минимум содержать большинство предыдущих ссылок. С каждым изменением в группе новая ссылка создаётся и присоединяется к цепочке. Между этими ссылками лежат блоки данных, которые представляют идентификаторы реальных данных (хэш, имя, тип и так далее). Снова они подписаны большинством предыдущих ссылок.
Вот изображение цепочки данных, которая будет построена. Но как это разделится в децентрализованную цепочку?
Разделение
Чтобы понять, как происходит разделение, посмотрите на картинку выше и на простое бинарное дерево xor. Помните, что у нас также есть понятие группы узлов. Так что пока возьмём для примера группу из двух участников.
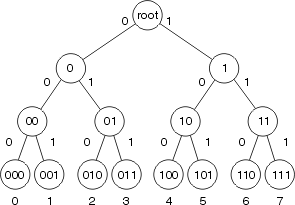
Процесс был бы таким:
Узел 1 запускает сеть, создаётся ссылка с одним участником.
Узел 2 стартует и продолжает цепочку дальше (она будет маленькой, так как присутствует только узел 1). Узел 1 затем пересылает ссылку на узел 2, подписаную узлом 1.
Узел 2 тогда пересылает ссылку на узел 1, подписанную узлом 2.
Теперь в цепочке есть две ссылки, одна на узел 1 сам по себе и следующая на узлы 1 и 2, оба связанные подписями между собой. Всё так и продолжается, так что я не буду наскучивать вам дальнейшим описанием.
Однако тогда узел 4, принимающий все соединения от узлов, будет иметь равное распределение (что значит 2 адреса узлов начинаются с 0 и другие 2 адреса узлов начинаются с 1) и цепочка разделяется! Два узла будут на ветке 0 и два узла остаются на ветке 1. Цепочка разделена, хотя поддерживает один и тот же блок «генезиса», который ссылается только на узел 1. Между этими ссылками в блоки добавляются данные (Put), редактируются (POST) или удаляются из сети, после чего каждый блок данных снова подписывается большинством предыдущих ссылок на блок (чтобы быть валидным).
Таким образом, чем больше узлов присоединяется к сети, тем больше происходит разделения цепочек по мере сетевого роста (чтобы узнать дополнительные детали, смотрите RFC и код). Это позволяет использовать несколько очень мощных функций, в которые мы не будем погружаться слишком глубоко, но приведём несколько в качестве примеров:
-Отображаются только те узлы, которые существуют в сети (то есть не может быть поддельных узлов).
-Узлы могут подтвердить состав группы.
-Узлы могут обеспечить доказуемую историю изменения состояния сети.
-Узлы могут перезапуститься и снова опубликовать безопасно те данные, которые должны существовать в сети.
-Сеть может сама восстановиться после того, как её связи перемешаны.
-Сеть может сама восстановиться после полного отключения электричества.
-Сеть может поддерживать открытые реестры для данных, которые должны быть доступны для проверки публично.
-Сеть может в индивидуальном порядке запомнить транзакцию (например, единичную транзакцию в safecoin можно запомнить по получателю или по переданной сумме).
-Сеть может обрабатывать данные любого типа (или только оплаченного типа).
-Поддельные узлы не могут присоединиться к цепочке без того, чтобы стать частью группы (что означает невозможность существования поддельных узлов).
-Поскольку блоки данных сохраняются между ссылками, которые поддаются проверке, гарантируется целостность данных.
-Поскольку целостность данных гарантирована, некоторые узлы могут содержать только идентификаторы, а не сами данные, или же содержать маленькое подмножество данных.
-Так как не всем узлам нужно хранить данные, трафик значительно меньше, чем в том случае, если бы все узлы хранили все данные всё время.
-Сеть может состоять из узлов с различными возможностями и использовать самый сильный узел в группе для выполнения действия, требующего наибольших усилий (например, узел с большим количеством места для хранения данных, более мощным процессором, более высокой пропускной способностью и так далее).
-Архивные узлы становятся одним из возможных состояний узла, они получают хорошее вознаграждение в safecoin, но им нужно бороться за место в группе,и при слишком большом количестве перезагрузок или пропущенных запросов другой узел займет его место.
-Состояние узлов сеть может легко измерить и оценить (важная особенность с точки зрения безопасности.)
Возможности также позволяют намного большее, например, легкое масштабирование или дальнейшее сокращение количества необходимых узлов. Есть сомнения, что полные возможности таких систем можно описать в этой короткой статье, но надо же с чего-то начинать?
Как?
Для дальнейшего продвижения технологии необходимы многие вещи, они включают, но не ограничиваются такими:
1. Должна быть завершена разработка на первом этапе (обеспечение постоянства и неизменности данных.)
2. Открытые дебаты, презентации и дискуссии должны иметь место.
3. Код должен быть написан.
4. Код должен быть протестирован.
5.Интеграция в существующие системы.
6. Финальное тестирование.
7. Переход к общедоступному использованию.
Действия по пунктам 1, 2, 3 & 4 продолжаются прямо сейчас. Пункт 5 требует изменений существующей таблицы маршрутизации SAFE, начатой в RFC. Пункт 4 может быть улучшен, если пункт 2 получит больше внимания. Пункт 6 это тестирование сообществом и пункт 7 также (так называемое альфа-тестирование).
Вывод
Созадётся впечатление, что цепочки данных являются следующей стадией эволюции децентрализованных систем. Они поддерживают данные любого типа, размера или формата, позволяя их пересмотреть позже и работая с ними децентрализованным и безопасным способом. И это не только физические данные сами по себе (и что ещё более важно), подтверждение целостности данных в определённой сети.
Работа над таким компонентом, как цепочки данных, довольно сложноя и связана с большим количеством обязательств. Суть системы довольно проста (помним, что чем проще, тем лучше) и каждый раз, когда пытаются вызвать в её работе различные проблемы, цепочка чинила сама себя. Это действительно не сложно запрограммировать, получив систему с невероятным уровнем безопасности, историческими данными о состоянии сети, возможностью внесения изменений в публикации — и всё это легко. И самой большой ошибкой было бы ограничиваться только несколькими узкими применениями.
